Datos, datos, datos. Valor, valor, valor. Y a ser posible en tiempo real. El concepto de inteligencia de negocio en tiempo real lleva tiempo dentro del mercado, pero hasta hace muy poco el número de empresas que la utilizaban era reducido. Hoy en día, Hadoop es la plataforma más utilizada para el análisis de grandes volúmenes de datos por su estabilidad, pero cuando se necesita cálculo en streaming, soluciones como Spark, Storm o DataTorrent RTS son una gran elección.
La falta de penetración de este tipo de prácticas en el mercado se debía a dos motivos fundamentales: el primero, evidente, era la ausencia de herramientas de inteligencia de negocio en tiempo real y el segundo, las soluciones existentes sólo se orientaban hacia el análisis de datos por lotes con unos costes elevados. Spark, Storm y DataTorrent RTS solucionan las dos circunstancias.
Apache Spark es, a buen seguro, la nueva gran estrella del análisis de los Big Data. Es una plataforma de código abierto para el procesamiento de datos en tiempo real, que puede ejecutarse y operarse con cuatro tipos de lenguajes distintos: Scala, la sintaxis en la que está escrita la plataforma; Python; R y también Java. La idea de Spark es ofrecer ventajas en el manejo de datos de entrada constante y con unas velocidades muy por encima de las que ofrece Hadoop MapReduce.
Algunas de sus características principales:
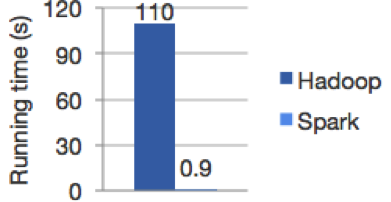
– Rapidez en procesos de cálculo en memoria y disco: Apache Spark promete una velocidad 100 veces más rápida en cálculo en memoria y 10 veces más ágil en disco que la que ofrece actualmente Hadoop MapReduce.
– Ejecución en plataformas de todo tipo: Spark se puede ejecutar en Hadoop, Apache Mesos, en EC2, en modo clúster independiente o en la nube. Además, Spark puede acceder a numerosas bases de datos como HDFS, Cassandra, HBase o S3, el almacén de datos de Amazon.
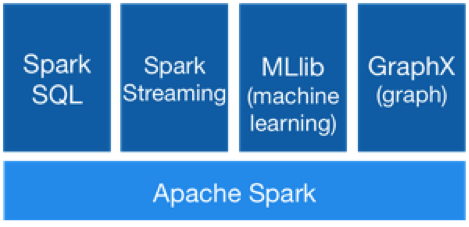
– Incorpora una serie de herramientas muy útiles para desarrolladores: la librería MLlib para implementar soluciones de aprendizaje automático y GraphX, la API de Spark para los servicios de computación con grafos.
– Dispone de otras herramientas interesantes: Spark Streaming, que permite el procesamiento de millones de datos entre los clústeres, y Spark SQL, que facilita la explotación de esos datos a través del lenguaje SQL.
Apache Storm es una sistema de computación distribuida en tiempo real y de código abierto. Permite el procesamiento sencillo y fiable de grandes volúmenes de datos en analítica (por ejemplo para el estudio de información de modalidad continua procedente de redes sociales), RPC distribuida, procesos de ETL…
Mientras que Hadoop se encarga del procesamiento de datos por lotes, Storm se encarga de hacerlo en tiempo real. En Hadoop los datos se introducen en su sistema de archivos (HDFS) y después se distribuyen a través de los nodos para ser procesados. Cuando esa tarea finaliza, la información regresa de los nodos al HDFS para ser utilizada. En Storm no hay un proceso con un origen y un final: el sistema se basa en la construcción de topologías de los Big Data para su transformación y análisis dentro de un proceso continuo de entrada constante de información.
Por esa razón Storm es algo más que un sistema de análisis de Big Data, es un sistema de procesamiento de eventos complejos (Complex Event Processing, CEP). Este tipo de soluciones son las que permiten a las empresas poder responder a la llegada de datos de forma repentina y continua (información recopilada en tiempo real por sensores, millones de comentarios generados en redes sociales como Twitter, WhatsApp o Facebook, transferencias bancarias…).
Además, para un desarrollador es especialmente interesante por varias razones:
– Se puede utilizar en varios lenguajes de programación. Storm está desarrollado en Clojure, un dialecto de Lisp que se ejecuta en Máquina Virtual Java (JVM, en sus siglas en inglés). Su gran fortaleza es que ofrece compatibilidad con componentes y aplicaciones escritos en varios lenguajes como Java, C#, Python, Scala, Perl o PHP.
DataTorrent RTS es una solución de código abierto para el procesamiento y análisis de grandes datos por lotes y también en tiempo real. Un todo en uno que pretende revolucionar no sólo lo que se puede hacer con el entorno Hadoop MapReduce, sino también lo que ya ofrecen tanto Spark como Storm en prestaciones. La plataforma es capaz de procesar miles de millones de eventos por segundo y recuperar cualquier caída de un nodo sin pérdida de datos e intervención humana.
Algunas de sus características fundamentales son:
– Procesamiento de eventos garantizado.
– Alto rendimiento en memoria.
– Es escalable.
– Tolerancia a fallos a nivel de plataforma.
– Fácil de ejecutar.
– Programación de aplicaciones en lenguaje Java.
Esta solución de Big Data proporciona mecanismos para la ingesta de información de muchas fuentes distintas, directamente de bases de datos externas o a través de su integración con las aplicaciones nativas de las empresas. DataTorrent RTS proporciona a los equipos técnicos un grupo de conectores previamente desarrollados para bases de datos SQL y NoSQL, Apache Sqoop, Apache Kafka, Apache Flume o redes sociales como Twitter… Todo aquello que genere datos.
Al final, estas herramientas de Big Data facilitan a las empresas conocer cuáles son las verdaderas oportunidades de negocio, acortando los plazos de estudio y análisis y reduciendo los costes. Es la batalla por el tiempo real y los modelos predictivos para ganar en competitividad y ganarle la partida a la competencia.
Una API es el mecanismo más útil para conectar dos softwares entre sí para el intercambio de mensajes o datos en formato estándar como XML o JSON. Así es como se convierte en un instrumento para buscar ingresos, abrirse al talento, innovar y automatizar procesos.
Las APIs pueden ser un gran apoyo a la hora de automatizar procesos empresariales Las empresas, a menudo con foco en las PYMES, dedican demasiadas horas-persona a procesos empresariales que consumen un tiempo precioso, incurriendo con ello en errores que una máquina jamás tendría. ¿Cómo puede la automatización de procesos empresariales (BPA) ayudar a estas […]
Se espera que durante los próximos años se regule el ‘open finance’, lo que dará lugar a un nuevo ecosistema de datos abiertos El open finance está abriéndose paso en el terreno legal mediante la consolidación de varias iniciativas que le darán blindaje jurídico. Una vez esto se haya completado, los clientes confiarán en un […]
Por favor, si no lo encuentras, recuerda revisar la sección de correo no deseado
×
El correo electrónico con tu ebook está en camino
Te hemos enviado dos mensajes. Uno con el ebook solicitado y otro para confirmar tu correo electrónico y empezar a recibir la newsletter de BBVA API_Market
×
TRATAMIENTO DE DATOS PERSONALES
¿Quién es el Responsable del tratamiento de tus datos personales?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA”), con domicilio social en Plaza de San Nicolás 4, 48005, Bilbao, España, C.I.F. A-48265169 Dirección de correo electrónico: contact.bbvaapimarket@bbva.com
¿Para qué y por qué utilizamos tus datos personales?
Para aquellas de las siguientes actividades para la que nos prestes tu consentimiento marcando la casilla correspondiente:
para la ejecución y gestión de tu solicitud, en concreto, recibir la newsletter de BBVA API_Market por medios electrónicos;
para enviarte comunicaciones comerciales, eventos y encuestas relativas a BBVA API_Market a la dirección de correo electrónico que nos hayas facilitado.
¿Durante cuánto tiempo conservaremos tus datos?
Conservaremos tus datos hasta que te des de baja para dejar de recibir nuestra newsletter o, en su caso, las comunicaciones comerciales, eventos y encuestas a las que te hayas suscrito. Tanto si te das de baja como si BBVA decide finalizar el servicio, tus datos serán eliminados.
¿Cómo puedo darme de baja para dejar de recibir la newsletter y/o comunicaciones de BBVA API_Market?
Puedes darte de baja en cualquier momento y sin necesidad de indicarnos ninguna justificación, remitiendo un correo electrónico a la siguiente dirección: contact.bbvaapimarket@bbva.com
¿A quién comunicaremos tus datos?
No cederemos tus datos personales a terceros, salvo que estemos obligados por una ley o que tú lo consientas previamente.
¿Cuáles son tus derechos cuando nos facilitas tus datos?
Consultar los datos personales que se incluyan en los ficheros de BBVA (derecho de acceso)
Solicitar la modificación de tus datos personales (derecho de rectificación)
Solicitar que no se traten tus datos personales (derecho de oposición)
Solicitar la supresión de tus datos personales (derecho de supresión)
Limitar el tratamiento de tus datos personales en los supuestos permitidos (limitación del tratamiento)
Recibir así como a transmitir a otra entidad, en formato electrónico, los datos personales que nos hayas facilitado y aquellos que se han obtenido de tu relación con BBVA (derecho de portabilidad)
Te responsabilizas de la veracidad de los datos personales que facilitas a BBVA y de mantenerlos debidamente actualizados.
Si consideras que no hemos tratado tus datos personales de acuerdo con la normativa, puedes contactar con el Delegado de Protección de Datos en la dirección dpogrupobbva@bbva.com
Puedes encontrar más información en el documento “Política de Protección de Datos Personales” de esta página web.
×
TRATAMIENTO DE DATOS PERSONALES
¿Quién es el Responsable del tratamiento de tus datos personales?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA”), con domicilio social en Plaza de San Nicolás 4, 48005, Bilbao, España, C.I.F. A-48265169 Dirección de correo electrónico:contact.bbvaapimarket@bbva.com
¿Para qué y por qué utilizamos tus datos personales?
Para la ejecución y gestión de tu solicitud, en concreto, descargar el e-book/s solicitado.
BBVA informa te informa de que, salvo que indiques tu oposición enviando un correo a la siguiente dirección:contact.bbvaapimarket@bbva.com, BBVA podrá enviarte comunicaciones comerciales, encuestas y eventos relativas a productos y/o servicios de BBVA API Market a través de medios electrónicos.
¿Durante cuánto tiempo conservaremos tus datos?
Conservaremos tus datos mientras sea necesario para la gestión de la solicitud, así como para el envío de comunicaciones comerciales, eventos y/o, encuestas. BBVAconservará tus datos hasta que te des de baja para dejar de recibir dichas comunicaciones o, en su caso, hasta que finalice el servicio.Después, destruiremos tus datos.
¿Cómo puedo darme de baja para dejar de recibir newsletters y/o comunicaciones de BBVA API Market?
Puedes darte de baja en cualquier momento y sin necesidad de indicarnos ninguna justificación, remitiendo un correo electrónico a la siguiente dirección:contact.bbvaapimarket@bbva.com
¿A quién comunicaremos tus datos?
No cederemos tus datos personales a terceros, salvo que estemos obligados por una ley o que tú lo consientas previamente.
¿Cuáles son tus derechos cuando nos facilitas tus datos?
Consultar los datos personales que se incluyan en los ficheros de BBVA (derecho de acceso)
Solicitar la modificación de tus datos personales (derecho de rectificación)
Solicitar que no se traten tus datos personales (derecho de oposición)
Solicitar la supresión de tus datos personales (derecho de supresión)
Limitar el tratamiento de tus datos personales en los supuestos permitidos (limitación del tratamiento)
Recibir así como a transmitir a otra entidad, en formato electrónico, los datos personales que nos hayas facilitado y aquellos que se han obtenido de tu relación con BBVA (derecho de portabilidad)
Puedes ejercitar ante BBVA los citados derechos a través de la siguiente dirección:contact.bbvaapimarket@bbva.com
Te responsabilizas de la veracidad de los datos personales que facilitas a BBVA y de mantenerlos debidamente actualizados.
Si consideras que no hemos tratado tus datos personales de acuerdo con la normativa, puedes contactar con el Delegado de Protección de Datos de BBVA en la dirección dpogrupobbva@bbva.com
Puedes encontrar más información en el documento “Política de Protección de Datos Personales ” de esta página web.
Banco Bilbao Vizcaya Argentaria, S.A. titular de este portal utiliza cookies y/o tecnologías similares propias y de terceros para fines técnicos, de personalización, analíticos, de publicidad comportamental o publicidad relacionada con tus preferencias sobre la base de un perfil elaborado a partir de tus hábitos de navegación (por ejemplo, páginas visitadas). Si deseas obtener información más detallada, consulta nuestra Política de Cookies.
Panel de configuración de cookies
Este es el configurador avanzado de cookies propias y de terceros. Aquí puedes modificar parámetros que afectarán directamente a tu experiencia de navegación en esta web.
Cookies técnicas (necesarias)
Estas cookies son importantes para darte acceso seguro a zonas con información personal o para reconocerte cuando inicias sesión.
Denominación
Titular
Duración
Finalidad
gobp.lang
BBVA
1 mes
Preferencia de idioma
aceptarCookies
BBVA
1 año
Configuración Cookies aceptadas
_abck
BBVA
1 año
Ayuda a protegerse contra los ataques de sitios web maliciosos
bm_sz
BBVA
4 horas
Ayuda a protegerse contra los ataques de sitios web maliciosos
ADRUM_BTs
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BT1
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BTa
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BT
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
xt_0d95e
Salesforce Marketing Cloud
Sesión
Recordar las preferencias del usuario (si las hay)
__s9744cdb192d044faa1bf201d29fafd1e
Salesforce Marketing Cloud
Sesión
Recordar las preferencias del usuario (si las hay)
wpml_browser_redirect_test
WPML
Sesión
Traducción de textos del portal
wp-wpml_current_language
WPML
24 horas
Traducción de textos del portal
Permiten medir, de forma anónima, el número de visitas o la actividad. Gracias a ellas podemos mejorar constantemente tu experiencia de navegación.
Dispones de una mejora continua en la experiencia de navegación.
Con tu selección no podemos ofrecerte una mejora continua en la experiencia de navegación.
Denominación
Titular
Duración
Finalidad
AMCV_***
Adobe Analytics
Sesión
ID de visitante único que se usan en las soluciones de Marketing Cloud
AMCVS_***
Adobe Analytics
2 años
ID de visitante único que se usan en las soluciones de Marketing Cloud
demdex (safari)
Adobe Analytics
180 días
Crear y almacenar identificadores únicos y persistentes
sessionID
Adobe Analytics
Sesión
Cookie interna de Launch usada para identificar al usuario
gpv_URL
Adobe Analytics
Sesión
plugin Adobe Analytics: getPreviousValue Capturar el valor de una determinada variable en la siguiente vista de página, en este caso la prop1
gpv_level1
Adobe Analytics
Sesión
Cookie utilizada para almacenar el levl1 del DataLayer de la página anterior.
gpv_pageIntent
Adobe Analytics
Sesión
Cookie utilizada para almacenar el pageIntent de la página anterior.
gpv_pageName
Adobe Analytics
Sesión
Cookie utilizada para almacenar el pagename de la página anterior.
aocs
Adobe Analytics
Sesión
Cookie que almacena los primeros valores recogidos al inicio de un proceso.
TTC
Adobe Analytics
Sesión
Cookie usada para almacenar el tiempo transcurrido entre el evento App Page Visit y App Completed.
TTCL
Adobe Analytics
Sesión
Cookie usada para almacenar el tiempo transcurrido entre el evento LogIn y App Completed.
s_cc
Adobe Analytics
Sesión
Determinar si las cookies están activas
s_hc
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_ht
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_nr
Adobe Analytics
2 años
Determinar el número de visitas de usuario
s_ppv
Adobe Analytics
Persistente
plugin Adobe Analytics: getPercentPageViewed Determinar el procentaje de página que visualiza un usuario
s_sq
Adobe Analytics
Sesión
Funcionalidades ClickMap/ActivityMap
s_tp
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_visit
Adobe Analytics
2 años
Cookie usada por Adobe para saber cunado una sesión se ha iniciado.
Permiten que la publicidad que te mostramos sea personalizada y relevante para ti. Gracias a estas cookies no verás anuncios que no te interesen.
Dispones de una publicidad adaptada a ti y a tus preferencias.
Con tu selección pierdes la personalización de la publicidad, solo verás anuncios genéricos.
Denominación
Titular
Duración
Finalidad
OT2
VersaTag
90 días
Cookie de VersaTag usada para almacenar un id de usuario y el numero de visitas del usuario.
u2
VersaTag
90 días
Cookie de VersaTag en la que se almacena el ID del usuario
TargetingInfo 2
MediaMind
1 año
Cookie que sirve para asignar un número unico random que genera MediaMind.
Estas cookies están relacionadas con características generales como, por ejemplo, el navegador que utilizas.
Dispones de una experiencia y contenidos personalizados.
Con tu selección no podemos ofrecerte una navegación y contenidos personalizados.
Denominación
Titular
Duración
Finalidad
mbox
Adobe Target
9 días
Cookie usada por Adobe Target para hacer test de personalizacion de experencia del usuario.
×
Parece que estás navegando desde México, así que vamos a mostrarte el contenido personalizado para tu localización. Cambiar
Parece que estás navegando desde España, así que vamos a mostrarte el contenido personalizado para tu localización. Cambiar
Selecciona el país
Para poder acceder al área privada y sandbox correspondiente, selecciona el país de las APIs que quieres utilizar.
×
×
×
Preferencias de Navegación
Elige el país del que quieres que te mostremos su contenido por defecto.