
En el mundo de Big Data, prácticamente cada mes aparece una nueva tecnología que viene enriqueciendo el ecosistema de Hadoop, aunque también puede llevar a la confusión al trabajador que empieza con estas nuevas tecnologías: son tantos tipos de software que es imposible recordarlos todos. En los últimos meses, sin embargo, Spark no sólo no ha caído en el olvido, sino que ha cogido cada vez más fuerza para llegar a convertirse en una tecnología estrella del Big Data.
En Pragsis ya llevábamos cierto tiempo probando este nuevo componente de Hadoop, pero durante la pasada semana tuve la oportunidad de asistir al curso de 3 días de Cloudera (curso que Pragsis incluirá pronto en su oferta de formaciones) y conocer en profundidad esta empresa, experiencia que hizo mejorar más aún mi opinión acerca de Spark.

Spark marcará un cambio en el mundo de Big Data
Spark ofrece múltiples ventajas con respecto a MapReduce-Hadoop:
– Big Data “in-memory”
Se trata de la cara más visible de Spark. Olvidad SAP-Hana y otras soluciones propietarias, por no decir “caras”. Spark permite realizar trabajos paralelizados totalmente en memoria, lo cual reduce mucho los tiempos de procesamiento. Sobre todo si se trata de unos procesos iterativos como los que se usan en el Machine Learning. En la imagen que se muestra a continuación, vemos el benchmark que encontraréis en https://spark.apache.org/ y que muestra el rendimiento de Spark respecto a Hadoop-MapReduce.
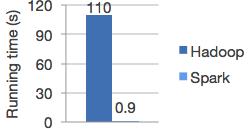
El hacer trabajos in memory no significa que tengamos que comprar servidores con terabytes de RAM (lo cual empieza a alejarse del “commodity hardware” que promociona Hadoop). Si algunos datos no caben en memoria, Spark seguirá trabajando y usará el disco duro para volcar los datos que no se necesitan en ese momento. También el programador tiene la posibilidad de definir prioridades, especificando qué datos se tienen que quedar siempre en memoria.
– Esquema de computación más flexible que MapReduce
Una limitación muy grande que siempre me ha molestado de MapReduce es la poca flexibilidad que este paradigma tiene a la hora de crear flujos de datos: solo puedes usar un esquema “Map -> Shuffle -> Reduce”. A veces sería interesante hacer un “Map -> Shuffle -> Reduce -> Shuffle -> Reduce” pero con MapReduce se tiene que transformar en un flujo “job 1(Map -> Shuffle -> Reduce) ; job 2 (Map -> Shuffle -> Reduce)” (obligando a tener una fase Map “identidad” que no sirve de nada, solo provoca perder tiempo).
Para optimizar esto, se inventó el framework Tez que sustituye el modelo anterior “MapShuffleReduce” por un flujo de ejecución con grafos acíclico dirigido (DAG):
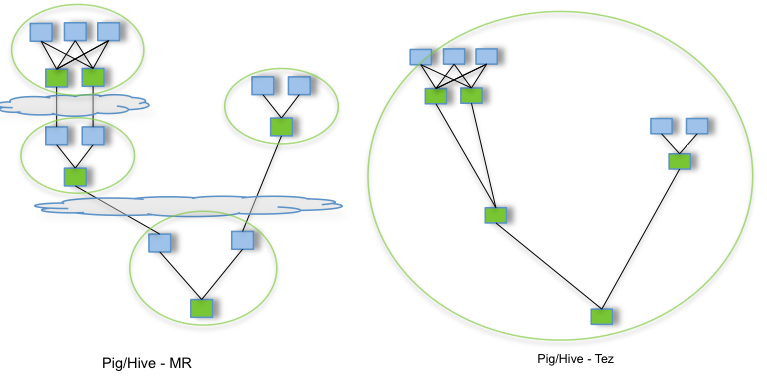
Spark también se dio cuenta de esta limitación de MapReduce y, al igual que Tez, propone unos workflows basados en DAG, reduciendo así aún más los tiempos de procesamiento.
– Unificación del mundo streaming-tiempo real y el mundo batch
Se trata de otro tema muy importante en el Big Data. Desde hace años se han buscado mecanismos para aportar el componente de tiempo real para Hadoop (framework inicialmente orientado a procesos batchs). Varios soluciones se han propuesto (HBase, Impala, Flume…) pero solo permiten cubrir en parte esta necesidad de tiempo real y de procesamiento en modo stream. Luego llegaron las famosas infraestructuras “lambda” y hasta “kappa”. Spark simplifica todo esto, en el sentido de que permite trabajar tanto en modo batch como en modo stream-tiempo real. Un mismo framework para unificar 2 mundos.

– Una forma de trabajar muy flexible
Spark ofrece una API tanto para Java como para Python y Scala: nada de lenguajes esotéricos que solo sirven para una tecnología (como puede ser el Pig Latin por ejemplo). Python y Scala presentan además la ventaja de poder usarse en modo scripting: no se pierde tiempo en iteraciones del tipo “editar un programa, compilarlo, ejecutarlo”. Basta con ejecutar los comandos en un intérprete de Spark para poder explotar los datos en nuestro cluster. Esto facilita mucho el labor de “Data Discovery” (ver último punto de este artículo).
Luego, es posible escribir una aplicación completa en Python, Java o Scala (este lenguaje siendo el mejor, por temas de rendimiento y por poder usar todas las funcionalidades de Spark), compilarla y ejecutarla en el cluster.
– Un ecosistema cada vez más completo
Al igual que MapReduce en su día, Spark aparece como un framework base en el cual se van desarrollando cada vez más aplicaciones y más avanzadas.
Actualmente tenemos:
– SparkSQL: para explotar los datos con un lenguaje SQL
– Spark Streaming: el cual mencionamos antes
– MLib: unas librerías para el Machine Learning
– GraphX: para la computación de grafos
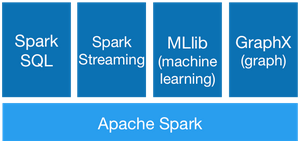
Imagino que estos software os sonarán bastante a los que ya conocéis Hive, Mahout y Giraph en Hadoop. Sabiendo el grado de adopción que tiene Spark actualmente y el interés que recibe por muchas empresas claves en el sector de Big Data (Yahoo, Facebook…), no me cabe la menor duda de que este ecosistema irá creciendo en los próximos meses.
Por todas estas razones, no es de extrañar que mucha gente considere Spark como el futuro de Hadoop. Una frase que oí en el curso de Cloudera fue “MapReduce no ofrece ninguna ventaja con respecto a Spark”.
Spark no es estable y todavía no listo para la producción
Spark suena a algo muy prometedor. Sin embargo, conviene matizar esta frase que dijo Cloudera. De hecho, el personal de Cloudera luego añadió que Spark todavía era un software joven y que no gozaba de toda la estabilidad de Hadoop-MapReduce. Una anécdota graciosa, por ejemplo, fue que durante los ejercicios del curso los alumnos descubrieron un bug en Spark y el instructor de Cloudera abrió una incidencia en el mismo curso. Algo que nunca me había pasado en otro curso…
Otro detalle relevante: durante el curso Cloudera reconoció que sí es cierto que varios de sus clientes están usando Spark, aunque por ahora no hay ninguno que lo esté usando en modo de producción.
Spark avanza muy rápidamente: en un año, ha pasado de la versión 0.7 a la versión 1.0. Esto es realmente bueno porque significa que hay muchas mejoras que se van incluyendo y que el proyecto está muy vivo. Sin embargo, tantos cambios de versiones también denotan una cierta falta de madurez y por lo tanto, de estabilidad.
Otro ejemplo de esto es la diversidad repentina de soluciones SQL en Hadoop:
– Al principio estuvo Hive.
– Cloudera sacó Impala para aportar el “tiempo real” en Hadoop.
– Hortonworks desarrolló la iniciativa Stinger para mejorar Hive y competir contra Impala.
– Shark, se desarrolló encima de Spark como un “Hive in memory”.
– Databricks decidió dejar de soportar Shark y refactorizar todo en un nuevo proyecto: SparkSQL.
– También acaba de aparecer una iniciativa de Hive encima de Spark. Parece que Cloudera apoya bastante este nuevo proyecto, lo cual muestra a Hortonworks que esta empresa se equivocó al intentar promocionar Impala.
Todo este lío de soluciones SQL encima de Hadoop no son de extrañar para este tipo de tecnologías tan novedosas. De hecho, considero que esta multitud de proyectos fomenta la competencia y por lo tanto es buena… al principio. Luego, como cualquier otro software, tiene que venir un momento de consolidación dónde solo destacarán unas 2 (3 como mucho) soluciones SQL claves y las otras habrán desaparecido. Razón de más para no precipitarse.
En resumen, Spark es una tecnología con mucho futuro pero respecto al presente yo no recomendaría invertir demasiados esfuerzos en ella, ni intentaría desarrollar aplicaciones muy avanzadas y aún menos tener soluciones en producción.
¿Qué hacer ahora? Probar y data discovery
Spark no es suficiente maduro para usarlo en un entorno de producción. ¿Esto significa que no hay que usarlo ahora mismo? Claro que no.
Primero, para muchas empresas tecnológicas es muy importante empezar a probar esta nueva tecnología. Sabiendo que irá a sustituir a MapReduce, una compañía de Big Data que quiere mantener su leadership no puede pasar de Spark. Pragsis lo tiene muy presente y por eso llevamos varios meses probando esta tecnología (pero sin hacer desarrollos masivos, como se explicó en la sección anterior).
En segundo lugar, creo que esta tecnología sí que aporta algo muy importante en los temas de “Data Discovery”. Al ser una solución que se puede usar en modo scripting, que permite extraer información de HDFS, con una capacidad de procesamiento muy buena además de escalable, y con una API muy avanzada asociada a librerías de machine learning, Spark aparece como una herramienta muy valiosa a la hora de explorar datos de forma interactiva. De hecho, mucho más valioso que Pig, una herramienta que se pensó en cierto momento para la exploración de datos.
Además, el Data Discovery es un proceso muy interactivo, que suele intervenir al principio de unos proyectos. Por lo tanto, estamos muy lejos de lo que puede ser un despliegue “en producción”. En este sentido, la falta de estabilidad de Spark no representa ningún problema.









