El lenguaje SQL es ya un viejo conocido entre los desarrolladores, usuarios de bases de datos y sysadmins. Lleva con nosotros desde 1974, y nos permite interactuar con los sistemas de bases de datos relacionales (RDBMS, por sus siglas en inglés: Relational DataBase Management System).

El SQL geoespacial es una especialización del SQL. Al igual que éste, permite definir y manipular datos de naturaleza relacional, mediante las tradicionales operaciones de INSERT/SELECT/UPDATE/DELETE. Pero existen dos diferencias fundamentales, que hace que el SQL geoespacial tenga entidad suficiente como para estudiarlo de manera separada:
-
Trabaja con tipos de datos espaciales, como geometrías (puntos, líneas, polígonos, etc) y datos raster (representación de un espacio en forma de una matriz de celdas, cada una de las cuáles contiene un valor significativo, como puede ser una componente de color RGB, en el caso de las imágenes, un valor de altura, en el caso de los mapas de elevación, una temperatura, etc)
-
Permite considerar las relaciones espaciales entre los tipos de datos mencionados.
Relaciones espaciales
El hecho de poder trabajar con relaciones espaciales es, por tanto, la característica más especial del SQL geoespacial. El Open Geospatial Consortium, se ha encargado de sistematizar y categorizar las relaciones entre elementos geométricos, definiendo el Dimensionally Extended nine-Intersection Model (DE-9IM). Este modelo especifica las relaciones que se pueden dar entre dos regiones geométricas (las relaciones con datos raster son más modernas, y aun carecen de especificaciones tan definidas como éstas) en un entorno bi-dimensional (2D), teniendo en cuenta que:
-
Todo elemento geométrico en 2D tiene 3 partes diferenciadas: el borde, el interior y el exterior.
-
Existen 3 tipos de elementos que pueden relacionarse en un espacio 2D: puntos (dimensión 0), líneas (dimensión 1) y polígonos (dimensión 2)
El problema de este modelo es que es excesivamente complejo para su uso práctico. De manera que, para hacerlo usable, se definieron una serie de predicados, que son los que implementan los gestores de bases de datos espaciales, como PostGIS. Estos predicados toman como argumento dos regiones en el espacio 2D, y devuelven como resultado TRUE (el predicado se cumple) o FALSE (el predicado no se cumple). Los predicados básicos son:
-
Contains (regionA, regionB): Si la región B está contenida dentro de la región A, este predicado devuelve TRUE. En otro caso, devuelve FALSE. Remarcamos dentro, para diferenciar este predicado del predicado Covers, que veremos más adelante.
-
Disjoints (regionA, regionB): Si las regiones A y B no tienen puntos en común, devuelve TRUE. En otro caso, devuelve FALSE. Es el predicado opuesto a Intersects, que veremos después
-
Touches (regionA, regionB): Si ambas regiones tienen bordes en común, pero no puntos interiores en común, este predicado devuelve TRUE. En otro caso, devuelve FALSE.
-
Equals (regionA, regionB): Si ambas regiones son topológicamente iguales, es decir, tanto sus interiores como sus límites coinciden, este predicado devuelve TRUE. En otro caso, devuelve FALSE. Nótese que Equals => Contains
-
Crosses (regionA, regionB): Si ambas regiones tienen algunos puntos interiores en común, pero no todos, este predicado devuelve TRUE. En otro caso, devuelve FALSE.
-
Overlaps (regionA, regionB): Si ambas regiones comparten espacio en 2D, ambas geometrías son de la misma dimensión y una no contiene totalmente a la otra, este predicado devuelve TRUE. Caso contrario, devuelve FALSE.
Hay otra serie de predicados derivados de estos, que también son frecuentes:
-
Within (regionB, regionA) = Contains(regionA, regionB)
-
Intersects (regionA, regionB) = NOT Disjoints(regionA, regionB)
-
Intersects (regionA, regionB) = Overlaps(regionA, regionB) OR Touches(regionA, regionB) OR Contains(regionA, regionB)
-
Covers (regionA, regionB) = Si ningún punto de la región B está fuera de la región A.
Llegados a este punto, para entender correctamente los predicados, hay algunas diferencias sutiles que tenemos que tener en cuenta, como que hay predicados muy similares, pero que se diferencian en el nivel de restricción que aplican para devolver TRUE:
-
Overlaps puede considerarse una versión más restrictiva de Intersects. Overlaps exige que ambas regiones sean de la misma dimensión y una de ellas no contenga totalmente a la otra. Por lo demás, los predicados son iguales.
-
Covers y Contains son también una versión más restrictiva del otro predicado. Se ve claramente en la siguiente imagen:
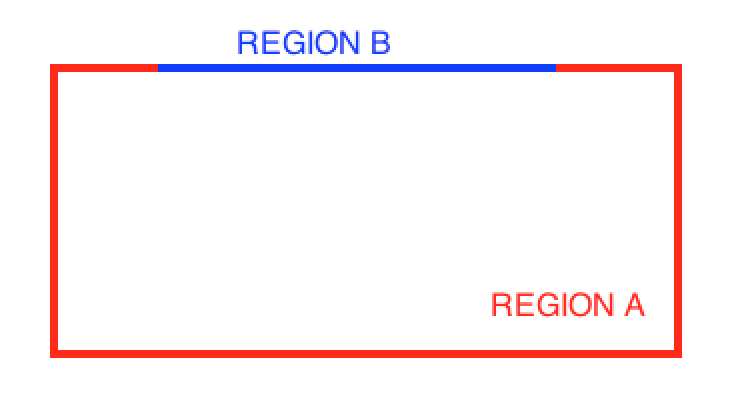
En una situación como ésta, el resultado de ambos predicados sería:
-
Contains(REGION A, REGION B) = FALSE
-
Covers(REGION A, REGION B) = TRUE
Esto sucede porque Contains es más restrictivo que Covers. Contains exige que al menos un punto del interior de B esté en el interior de A. En este caso, todos los puntos de B están en el borde de A, y ninguno en su interior.
La mayoría de bases de datos espaciales proporcionan una implementación de estos predicados, además de otros adicionales. En este enlace, se explican con más profundidad.
En nuestro caso, estamos especialmente interesados en conocer la implementación realizada en PostGIS. PostGIS es la extensión espacial de la base de datos PostgreSQL. Tanto PostgreSQL como PostGIS tienen licencia Open Source y son gratuitos, además de tener un nivel de madurez alto y una inmensa comunidad detrás. Es por ello que es especialmente sencillo acceder a ellos, para poder comenzar a experimentar con SQL geoespacial. Existen instaladores de ambas herramientas tanto para sistemas Windows, como Linux y Mac OS. Y por supuesto, para aquellos que prefieran experimentar con el lenguaje sin necesidad de instalar nada en sus máquinas, existe CartoDB. Basta con registrarse para obtener una cuenta gratuita, que permite crear hasta 5 tablas y ejecutar consultas SQL en cuestión de minutos.
Índices espaciales
Para terminar con esta introducción, debemos tener en cuenta la existencia de otro elemento fundamental a la hora de trabajar con SQL geoespacial: el índice espacial.
Los índices son bien conocidos en bases de datos relacionales. Se trata de estructuras de datos que permiten acceder más rápidamente a los registros de una base de datos. Para ello, simplemente se almacenan las entradas más usadas de la tabla en una zona de memoria de acceso rápido.
El problema con las bases de datos espaciales es que los índices tradicionales no funcionan bien para el tipo de operaciones en las que podemos estar interesados, como obtener los puntos más cercanos a una ubicación, calcular la distancia entre dos puntos, o determinar si un polígono intersecta con otro. Es por eso que, en las tablas de datos que contienen columnas de naturaleza espacial, se suelen crear índices espaciales, que hacen que las consultas se ejecuten hasta varios órdenes de magnitud más rápido.
En posts posteriores, profundizaremos más en SQL geoespacial, viendo algunos ejemplos concretos, así como la utilización de datos de tipo raster junto con datos de tipo geométrico.









