The world of Big Data is moving fast. New technologies are emerging that offer the promise of managing and analyzing large volumes of data faster, in a more scalable way and with cheaper implementation and maintenance costs. The truth is that Apache Spark, the open source distributed computing platform, is the most notable among them because it provides added value with respect to its predecessors.
There are many features that make Spark a special platform, but we could summarize them into five major aspects: it is an open source platform with a very active community; it is a fast tool; it is unified; it features an interactive console that is convenient for developers; and it also has an API for working with Big Data.
1. An open source platform with an active community
One of the most interesting aspects of an open source solution is how active its community is. The developer community enhances the platform’s features and helps other programmers implement solutions or solve problems.
The Apache Spark community is increasingly active: in September 2013 there were over 113,000 lines of code; one year later, the figure was in excess of 296,000; and in September 2015, the volume of lines of code already reaches a record level: 620,300.
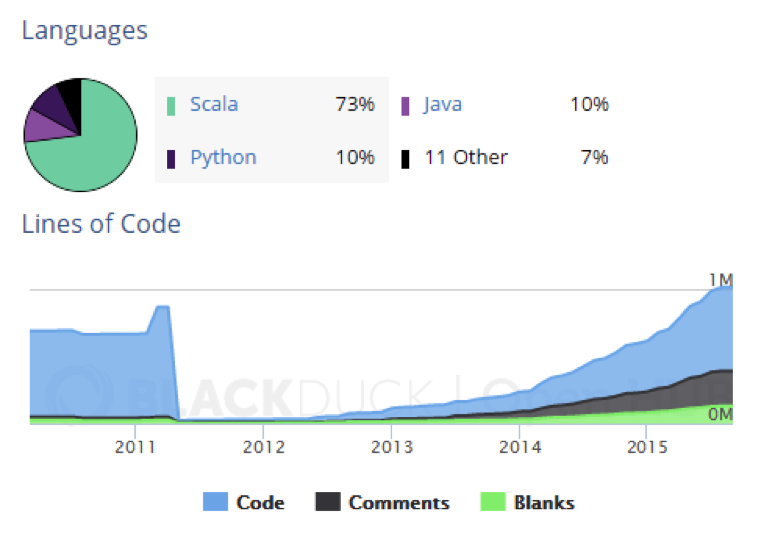
In addition, the community has continued to grow in the number of programmers since June 2012. On that date, four new contributors signed up. In June 2015, three years later, the figure was 128. In July 2015, the last date for which data is available, 137 joined the project.
2. A fast platform
One of the most striking features of Spark is that, despite being an open source platform, it is extremely fast, very much faster than some proprietary solutions. Why is it so fast? Apache Spark enables programmers to perform operations on a large volume of data in clusters quickly and with fault tolerance. When we have to handle algorithms, work in-memory and not on disk, it improves performance.
Thus, in terms of machine learning, Spark offers much faster in-memory computation times than any other platform. Caching the data makes the iteration of machine learning algorithms with the data more efficient. The transformations of that data are also stored in memory, without having to access the disk.
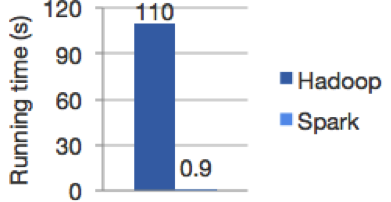
On its website there is a benchmark test that shows Spark’s performance relative to MapReduce: from 10 to 100 times faster.
In this in-memory data processing, the team of developers have enough flexibility to choose what data remains in-memory and what data can be dumped onto the hard disk because it is not needed at that time. This releases a great deal of processing power, increasing its efficiency.
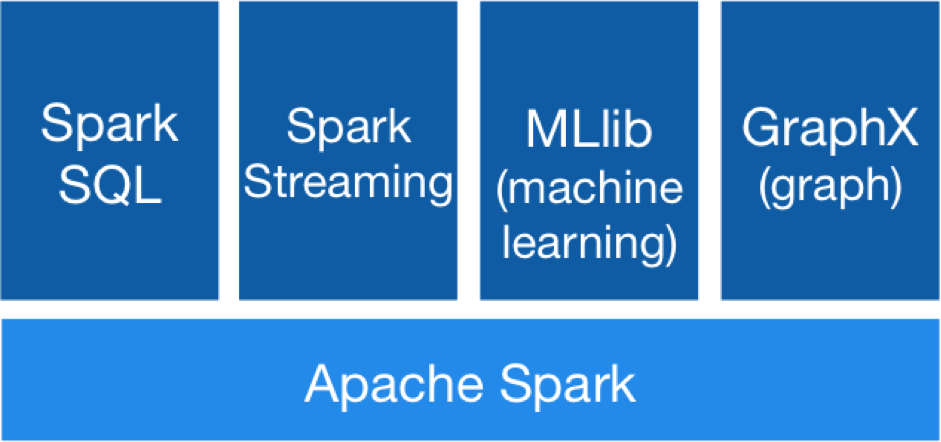
3. A unified platform for data management
This is one of the most distinctive features of Apache Spark. It is a platform of platforms. An ‘all-in-one’ that greatly speeds up the operation and maintenance of its solutions. It combines:
– Spark SQL: it enables querying of structured data using an SQL language or an API, that can be used with Java, Scala, Python or R.
– Spark Streaming: whereas MapReduce only processes data in batches, Spark can manage large volumes of data in real time. The data can thus be analyzed as it arrives, with no latency and through a management process in continuous motion.
– MLlib (Machine Learning): this tool contains algorithms that provide Apache Spark with many utilities, such as logistic regression and support vector machines (SVM); Bayesian regression tree models; least square techniques; Gaussian mixture models; average K conglomerate analysis; latent Dirichlet allocation (LDA); singular value decomposition (SVD); principal component analysis (PCA); linear regression; isotonic regression…
– GraphX: this is a graphics processing framework. It provides an API for making graphs with the data. It was originally a separate project by AMPLab and Databricks of the University of California, Berkeley, like Spark, but it later joined the Apache Software Foundation.
4. Interactive console
One benefit of working with Spark are the interactive consoles it offers for two of the languages that can be used for programming: Scala (that runs in a Java Virtual Machine – JVM) and Python. These consoles enable the data to be analyzed interactively, through a connection to the clusters.
To take one example, Python developers can and frequently use IPython to run Spark’s API in Python (PySpark). IPython is a system for creating executable documents. IPython enables the integration of formatted text (using the Markdown markup language), executable Python code, mathematical formulas with LaTeX, and graphics and visualizations with the library in Python, matplotlib.
5. A great API for working with data
Apache Spark has native APIs for the Scala, Python and Java programming languages. This set of APIs enables programmers to develop applications in these syntaxes, that can be run on the open source platform. The APIs enable interaction with the data from:
– The Hadoop File System (HDFS).
– The open source NoSQL database HBase.
– The open source NoSQL database Apache Cassandra.
The APIs are used for performing two types of operations on the data:
– Transforming a group of data.
– Applying operations on the data to obtain a result.
Follow us on @BBVAAPIMarket